Introduction
CO2 Air Quality Monitoring System with Telegram notification


Purpose
The aim of this project is to receive Telegram notification when CO2 air quality is higher than certain level from Wemos. It uses MH-Z19B sensor to measure CO2 air quality and visualizes the result with Google Chart API. CO2 measurement data is presented in gauge type. We can check current status via web browser using WiFi connection.
This project is based on our previous projects,
- IoT Laboratory: CO2 air quality monitor with Line notification V2
- IoT Laboratory: CO2 air quality monitor with Line notification
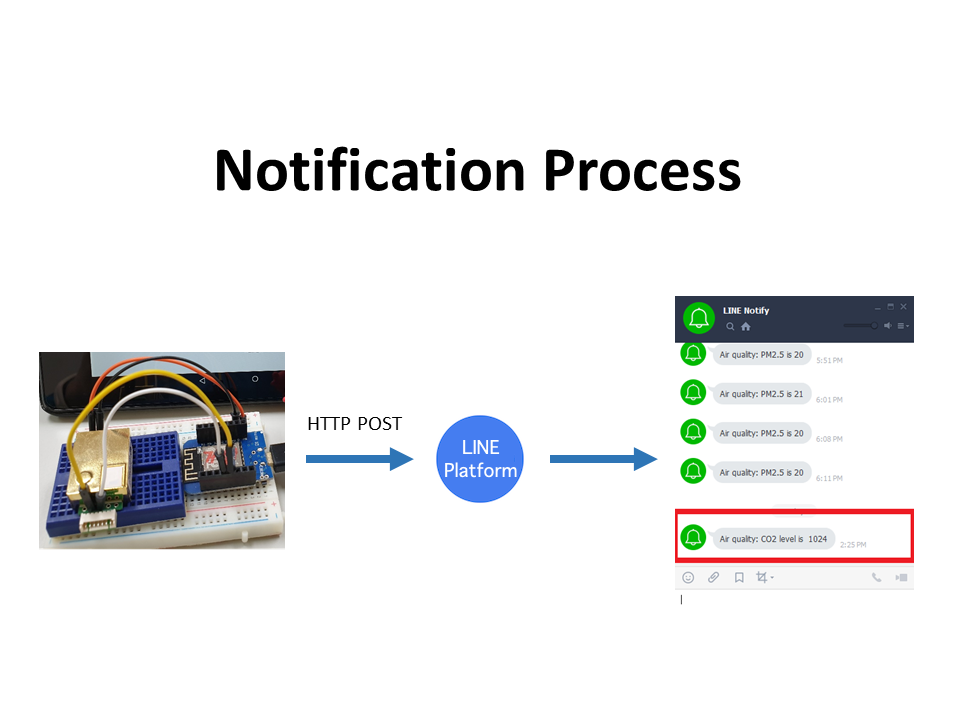
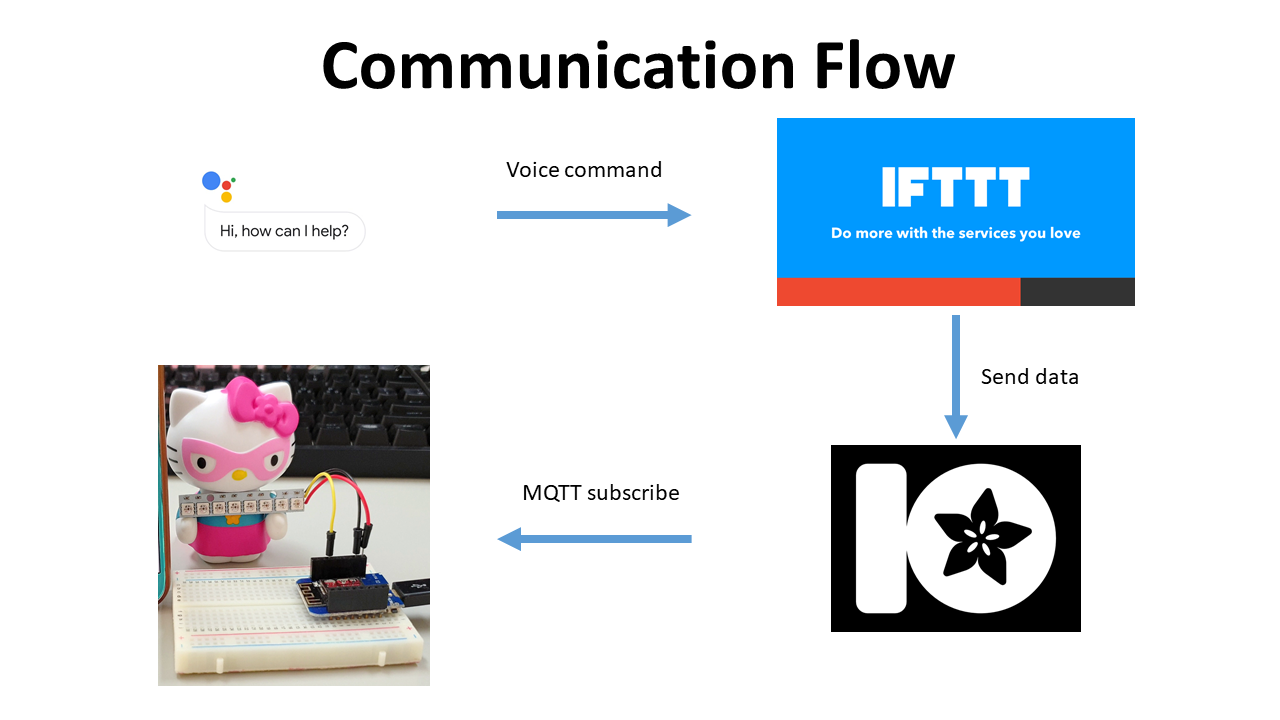
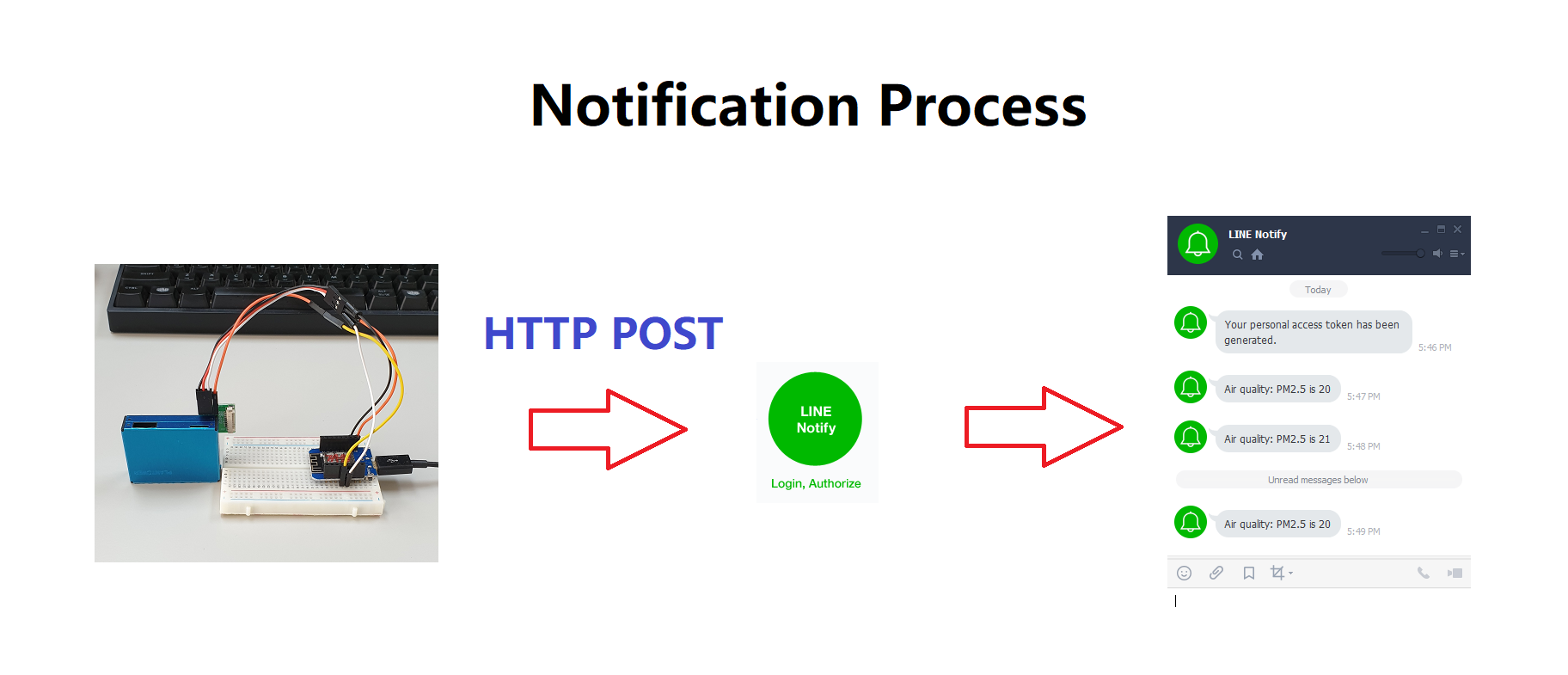
It replaces Line notification with Telegram notification. A user will be notified by Telegram when the level of CO2 hits a certain level which is specified by the user in the source code. The entire process for sending Telegram notification is like below. Wemos sends HTTP GET request to Telegram server, then, the message will be delivered to our Telegram messenger.

For web server, we use ESPAsyncWebServer library and it is available at github. Additionally, we need to install EPS8266 Sketch Data Upload to upload web server related files to Wemos. For example, in this project, we use HTML, Javacript, and CSS files under data directory. In other words, we need to upload sketch and web related files separately.
Features
This project is based on our previous projects,
- IoT Laboratory: CO2 air quality monitor with Line notification V2
- IoT Laboratory: CO2 air quality monitor with Line notification
It replaces Line notification with Telegram notification. A user will be notified by Telegram when the level of CO2 hits a certain level which is specified by the user in the source code. The entire process for sending Telegram notification is like below. Wemos sends HTTP GET request to Telegram server, then, the message will be delivered to our Telegram messenger.
For web server, we use ESPAsyncWebServer library and it is available at github. Additionally, we need to install EPS8266 Sketch Data Upload to upload web server related files to Wemos. For example, in this project, we use HTML, Javacript, and CSS files under data directory. In other words, we need to upload sketch and web related files separately.
Prerequisites
- ESP8266 package for Arduino IDE
- EPS8266 Sketch Data Upload
- ESPAsyncTCP Library
- ESPAsyncWebServer Library
- Telegram Bot token and chat id
Hardware
-Wemos D1 mini : US$1.77 on Aliexpress
-MH-Z19B CO2 sensor : US$17.90 on Aliexpress
Step 1. Setup hardware
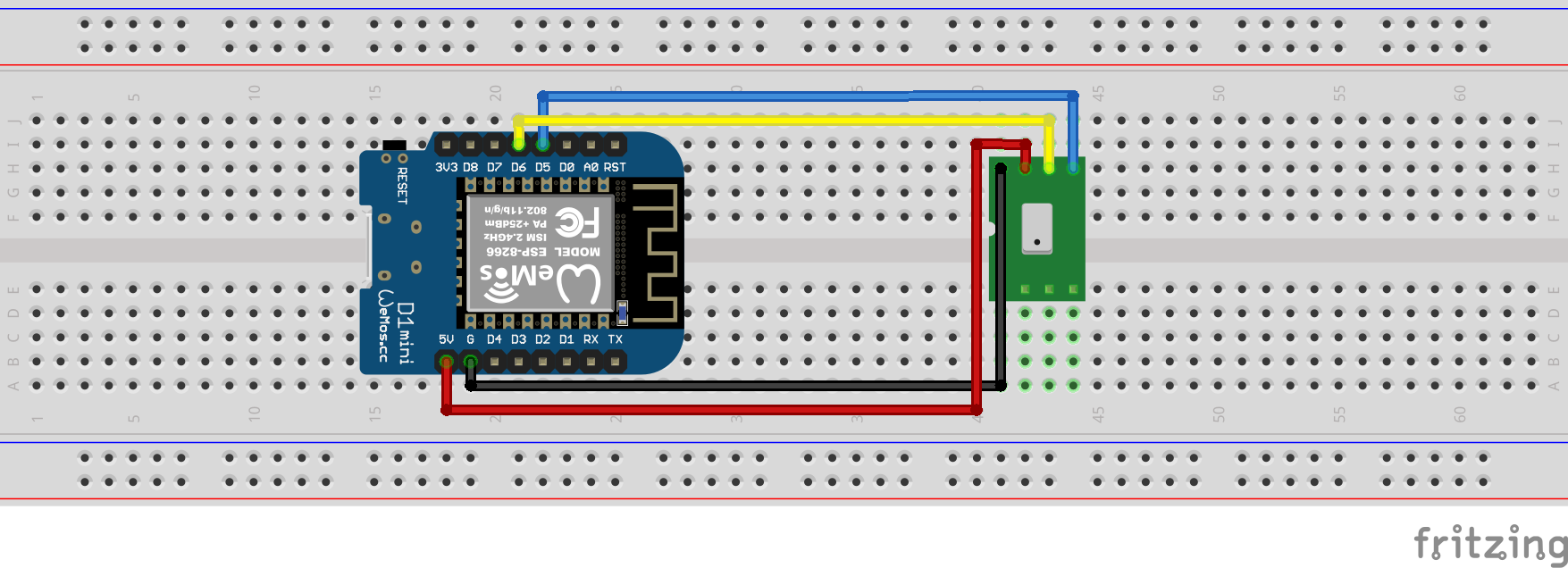
MH-Z19B sensor has many pins, but, we only use TX, RX, VCC, and GND pins. Connect TX of MH-Z19B to D5 of Wemos, RX to D6, VCC to 5V, and GND to G. Finally, connect micro usb to Wemos for uploading firmware, and check serial monitor and serial plotter in Android IDE to make sure the sensor works correctly.
Step 2. Create Telegram account and bot
To be able to receive Telegram notification, we need two things; bot token and chat id. Bot token is generated automatically when we create a new bot. Then, send a request on web browser to Telegram. After that, Telegram sends a response with chat id in it. This process looks a little bit complicated at first, but, I found an easy and useful tutorial on Youtube. It would be extremely helpful if you are not familiar with Telegram.
Step 3. Upload sketch to Wemos D1 mini
This step is to upload sketch to Wemos as usual. In the following sketch, following values need to be modified with your own.
- WIFI_SSID : Name of WiFi router
- WIFI_PASS : Password of WiFi router
- TG_TOKEN : Token of Telegram bot
- TG_CHAT_ID : Chat id that the bot will be sending message to
In this example sketch, it send Line notification only when CO2 density hit 1000 or higher. And before sending again it waits 10 minutes. These values can be changed by user.
- notifyLevel : CO2 threshold for Line notification
- notifyInterval : Waiting time (specify in milliseconds)
Step 4. Upload data to Wemos D1 mini
This step is to upload web server related files (HTML, Javascript, CSS) to Wemos. These files are located in directory named data. Click "ESP8266 Sketch Data Upload" under Tools menu in Arduino IDE to upload these files to Wemos. Once it shows the measurement data, it will refresh every 3 seconds automatically.
HTML file
On web interface, the size of gauge is defined in width, height of options variable. Just change these values to customize chart size. And if you want to modify refresh rate, change the value of 30000 in setInterval function to other value.
CSS file
Javascript file
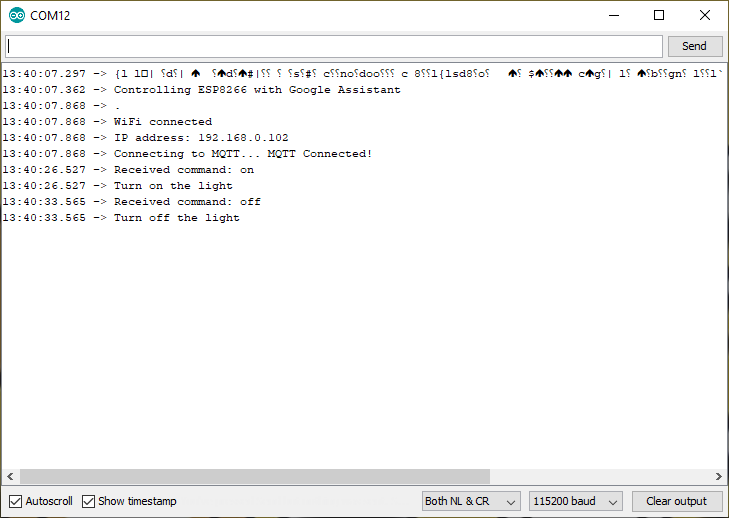
After uploading firmware, Wemos restarts itself automatically. Once Wemos D1 mini has restarted, serial monitor shows a welcome message, CO2 threshold, and waiting period. When CO2 is higher than threshold it will send Telegram notification to the user as below.

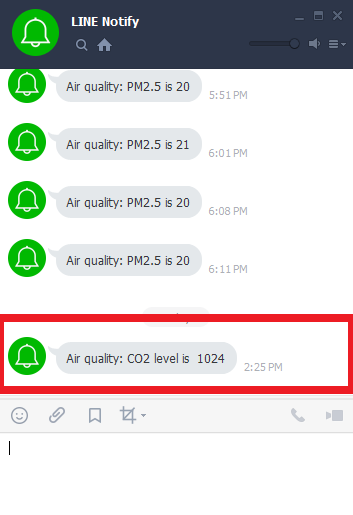
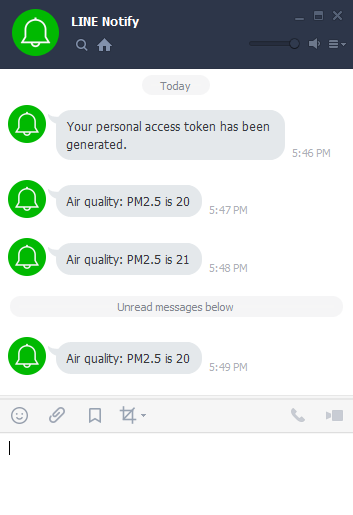
In this project, Wemos sends two types of message. The first type is for informing IP address of itself. And the second type is for notification with measured CO2 density.

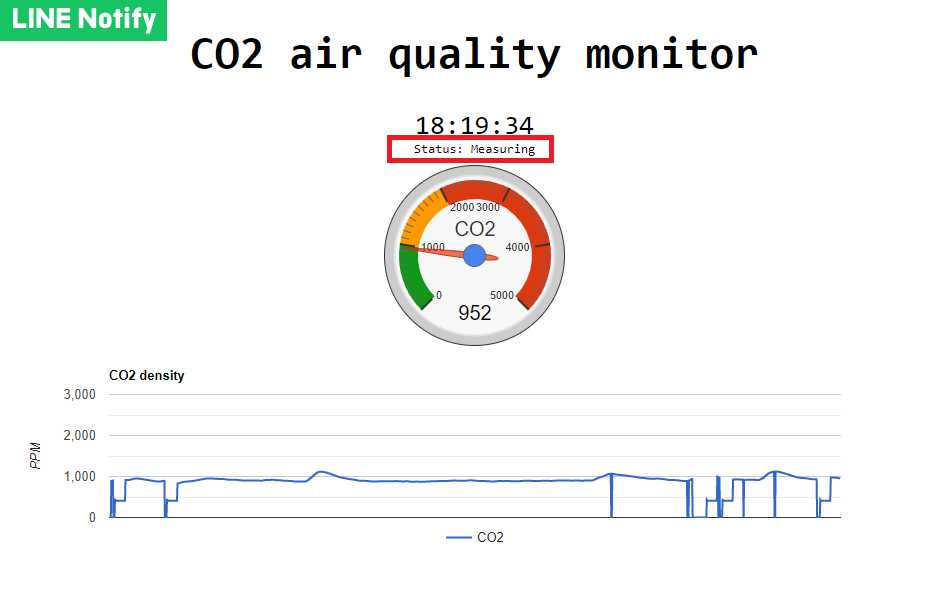
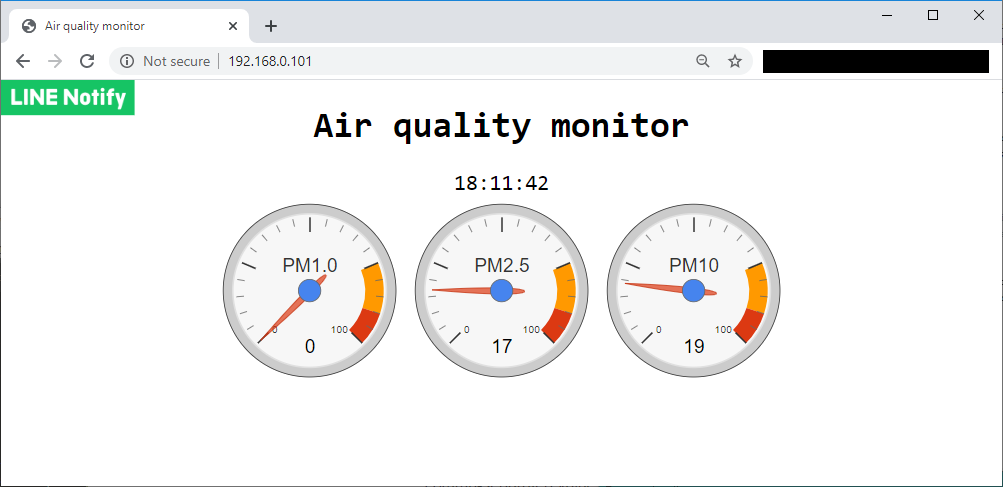
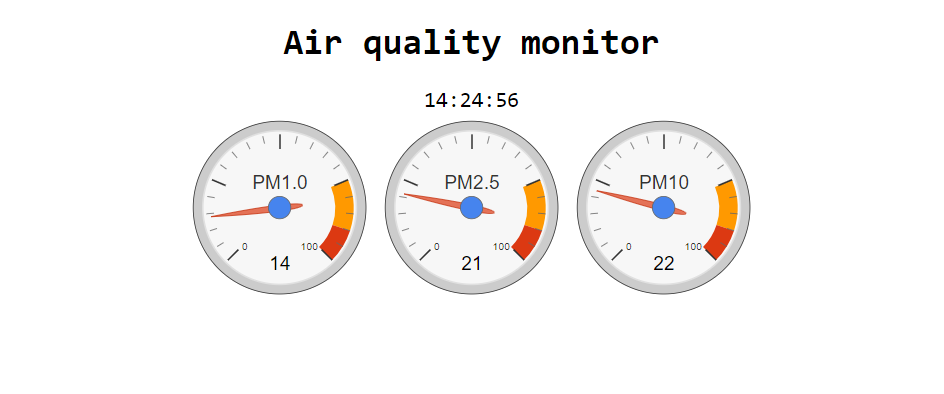
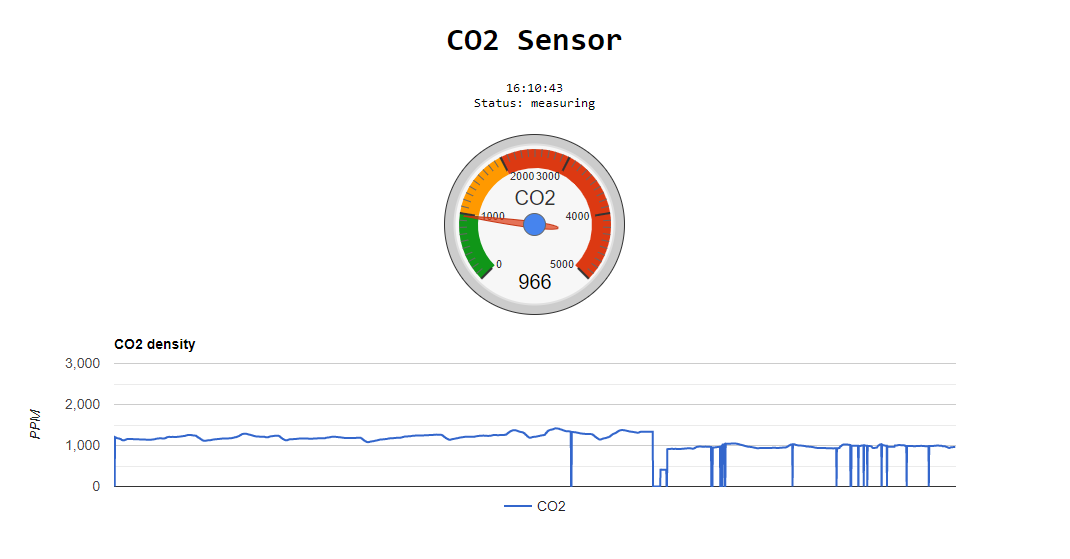
We can use web browser to connect to the device, then it will show current time and visualized information, which is based on Google Chart API. It will refresh itself every 3 seconds automatically.
In this project, Wemos uses softwareserial library to communicate with MH-Z19B sensor. However, this library will be interfered by other library which uses timer or interrupt internally. Originally, I plant to use Adafruit Neopixel library in this project to lit some of LED strip, but, it interfered the communication of softwareserial library. So, I decided not to use LED strip for this project. One possible work around would be to ESP32 board which has more than one hardware serial.
- EPS8266 Sketch Data Upload
- ESPAsyncTCP Library
- ESPAsyncWebServer Library
- Telegram Bot token and chat id
Requirements
-Wemos D1 mini : US$1.77 on Aliexpress
-MH-Z19B CO2 sensor : US$17.90 on Aliexpress
Instructions
MH-Z19B sensor has many pins, but, we only use TX, RX, VCC, and GND pins. Connect TX of MH-Z19B to D5 of Wemos, RX to D6, VCC to 5V, and GND to G. Finally, connect micro usb to Wemos for uploading firmware, and check serial monitor and serial plotter in Android IDE to make sure the sensor works correctly.
Step 2. Create Telegram account and bot
To be able to receive Telegram notification, we need two things; bot token and chat id. Bot token is generated automatically when we create a new bot. Then, send a request on web browser to Telegram. After that, Telegram sends a response with chat id in it. This process looks a little bit complicated at first, but, I found an easy and useful tutorial on Youtube. It would be extremely helpful if you are not familiar with Telegram.
Step 3. Upload sketch to Wemos D1 mini
This step is to upload sketch to Wemos as usual. In the following sketch, following values need to be modified with your own.
- WIFI_SSID : Name of WiFi router
- WIFI_PASS : Password of WiFi router
- TG_TOKEN : Token of Telegram bot
- TG_CHAT_ID : Chat id that the bot will be sending message to
In this example sketch, it send Line notification only when CO2 density hit 1000 or higher. And before sending again it waits 10 minutes. These values can be changed by user.
- notifyLevel : CO2 threshold for Line notification
- notifyInterval : Waiting time (specify in milliseconds)
Step 4. Upload data to Wemos D1 mini
This step is to upload web server related files (HTML, Javascript, CSS) to Wemos. These files are located in directory named data. Click "ESP8266 Sketch Data Upload" under Tools menu in Arduino IDE to upload these files to Wemos. Once it shows the measurement data, it will refresh every 3 seconds automatically.
HTML file
On web interface, the size of gauge is defined in width, height of options variable. Just change these values to customize chart size. And if you want to modify refresh rate, change the value of 30000 in setInterval function to other value.
CSS file
Javascript file
Results
In this project, Wemos sends two types of message. The first type is for informing IP address of itself. And the second type is for notification with measured CO2 density.
We can use web browser to connect to the device, then it will show current time and visualized information, which is based on Google Chart API. It will refresh itself every 3 seconds automatically.
Cautious!
References
- IoT Laboratory: ESP8266-based WiFi air quality monitoring system using PMS7003 sensor with Google Chart visualization
- IoT Laboratory: ESP8266-based WiFi air quality monitoring system using PMS7003 sensor
- IoT Laboratory: ESP8266-based WiFi air quality monitoring system using PMS7003 sensor
- IoT Laboratory: ESP8266-based air quality monitoring system using PMS7003 sensor
- IoT Laboratory: ESP8266-based WiFi MQTT air quality monitoring system using PMS7003 sensor
- IoT Laboratory: ESP8266-based WiFi MQTT air quality monitoring system using PMS7003 sensor
- Arduino WiFiClient
- EPS8266 Sketch Data Upload
- ESPAsyncTCP Library
- ESPAsyncWebServer Library
- Google Chart : Gauge
- Telegram Bot token and chat id
- How To Create Telegram Bot
Source codes at github- EPS8266 Sketch Data Upload
- ESPAsyncTCP Library
- ESPAsyncWebServer Library
- Google Chart : Gauge
- Telegram Bot token and chat id
- How To Create Telegram Bot