Introduction
With more than one GPU programming interfaces available, there is a great interest in converting regular program to GPU program with two frequently asked questions.
- How much performance improvement can we expect from it?
- Which programming interface is better than others?
In this post, the performance of CPU and GPU are compared for vector addition and matrix multiplication, which are widely used building blocks for scientific application.
Additionally, the performance of OpenCL, CUDA, and PGI Accelerator on NVIDIA's M2050GPU are analyzed to compare different GPU programming interfaces.
No - for vector addition
Yes - for matrix multiplication
Figure 1 shows 'elapsed time' for vector addition on CPU and GPU. CPU is about 4 times faster than GPU in this experiment.
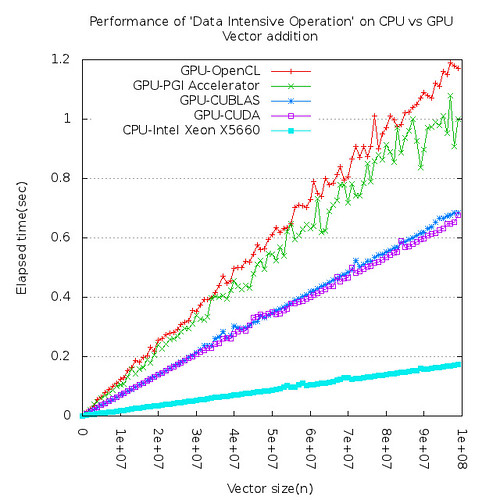 | ||
| Figure 1. CPU is faster than GPU for vector addition |
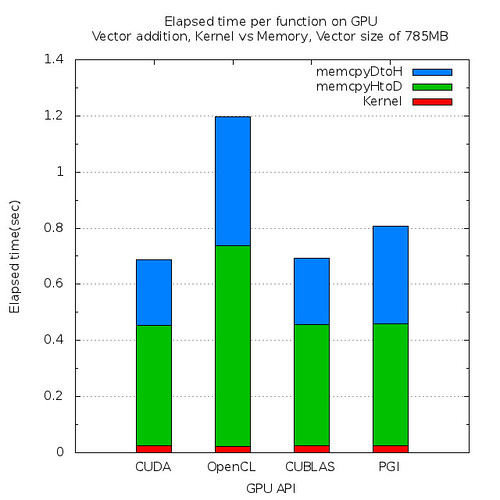 |
| Figure 2. Elapsed time per function on GPU |
Large vectors need to be copied from CPU memory to GPU memory through relatively slow PCIe bus and it overshadows the higher computational capability of GPU. Figure 2 tells us that most of time on GPU are used to copy data.
However, for matrix multiplication, GPU is 200 times or more faster than CPU. Computing intensive calculation such as matrix multiplication is best candidate for GPU.
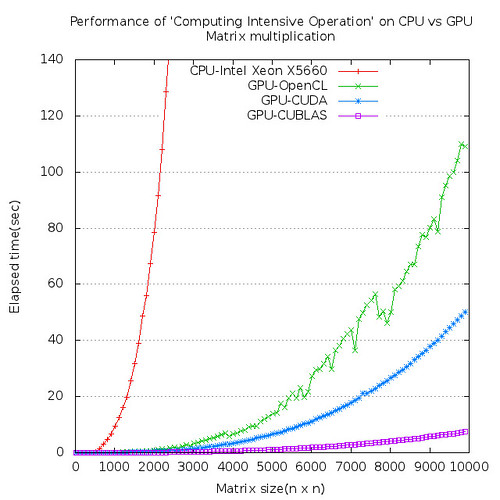 |
| Figure 3. GPU is extremely faster than CPU for matrix multiplication |
Most of times are consumed for computations and data transfer time is almost negligible for matrix multiplication on GPU.
 |
| Figure 4. Elapsed time per function on GPU |
2. Is OpenCL better than CUDA?
Yes for compatibility
??? for performance
CUDA is about 5% faster than OpenCL for matrix multiplication in this experiment on NVIDIA M2050 platform.
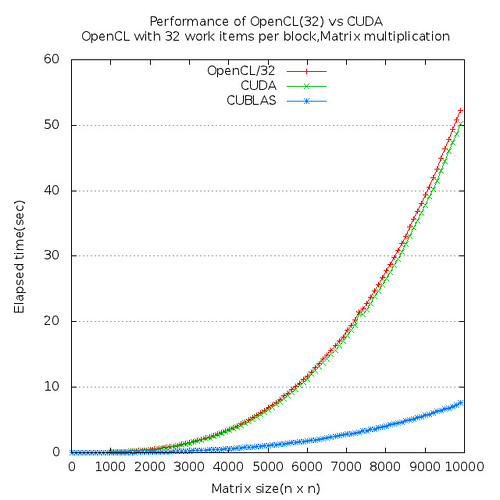
Conclusion
To be able to get maximum performance out of NVIDIA GPU, try to take advantage of CUBLAS as much as possible. If there is any chance that your program need to be running on different GPU platform such as AMD or INTEL, etc, then use OpenCL for compatibility.
If you are interested in full article about this experiment, check here.
I suppose that the vector addition numbers include the memcopies also. Because you have a 5x difference in mem. bandwidth.
ReplyDelete